之前因為工作的關係,需要常常打電話給康是美門市。
為了能方便使用,我寫了一支小程式,能夠從康是美官方網站抓取全門市列表,存成CSV檔。
再利用MS Excel內建的VBA,將資料作整理、排序、套用格式…等。
歷程
前前後後試了至少五種版本,現在已經離職了所以已經用不到,當作練習而已。
VBA
想抓取康是美門市列表,用Excel VBA就可以達成,這也是我一開始的作法。
優點:只要電腦有安裝Excel就可以使用VBA。且把網頁資料匯入到Excel不用自己解析html。
缺點:覺得整理資料的方法比較不穩健,且效能上遇到一些問題,一直無法解開。
R - xml2
後來學了R語言之後,就改用R語言做做看。
第一版是用xml2套件,用xpath的方式。
優點:解析網頁的方法比用VBA好多了,重點是能解決效能的問題。
缺點:需要安裝R的環境。
R的環境其實很好架,但就無法直接在別的電腦執行,且程式無法直接打包成執行檔。
還有我不習慣R的程式碼,寫得很亂,自己不滿意。
R - rvest
第二版,因為發現R比較多人用rvest套件,所以我就決定來試試看。
優點:rvest語法簡潔多了,程式碼可讀性提昇,寫起來也比較快。
缺點:同第一版。要安裝R的環境、無法打包執行檔、R的語法我不習慣。
Python - BeautifulSoup
優點:比用R簡潔更多,寫起來更快。
缺點:python的環境沒有R那麼好架,之前好幾度失敗。
現在能快速架起來可能是因為改用Ubuntu的關係(?)
爬蟲的第一步:觀察網頁特性
資料來源:康是美官方網站
Welcome to 康是美
門市查詢
門市查詢-結果
首先進入康是美門市查詢的頁面。
左邊的區塊有「縣市」、「行政區」、「店名」、「關鍵字」、「專櫃名」這些條件可以輸入。
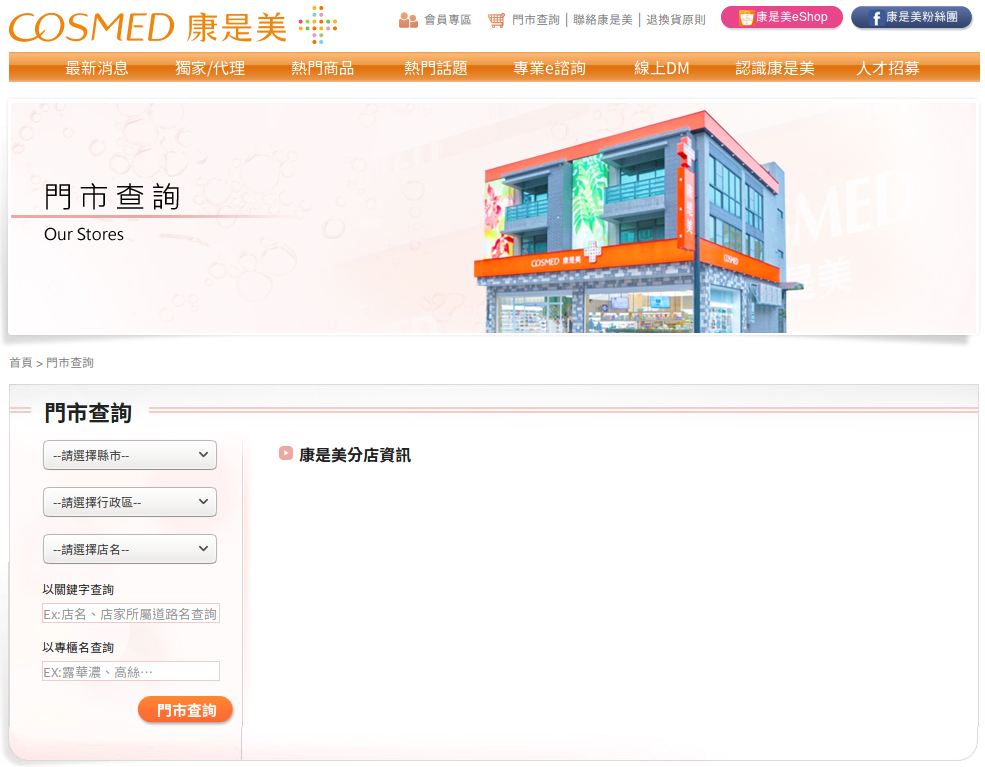
若不輸入任何條件,直接按下「門市查詢」的按鈕,就可以跑出全部門市的資料。
六間門市為一頁,下方有超連結可以切換頁面。
網頁上所呈現的資訊有:「門市名稱」、「門市地址」、「門市電話」、「營業時間」。
其中「門市名稱」為超連結,超連結的內容是該門市的頁面,頁面中呈現更詳細的門市資訊。
而「營業時間」的內容包含換行字元。

目前總共有67頁,這個是最後一頁的畫面。

觀察網址
再來觀察網址,
若由門市查詢不輸入任何條件,直接按下「門市查詢」:
https://www.cosmed.com.tw/Contact/Shop_list.aspx?City=&District=&ID=&KeyWord=&Shop=
移除後面的參數,可簡化為:
https://www.cosmed.com.tw/Contact/Shop_list.aspx?
若輸入簡化後的網址,也能帶出相同頁面。
若切換到第二頁,可以看到網址列出現了頁面的參數(pg=2)
https://www.cosmed.com.tw/Contact/Shop_list.aspx?pg=2&City=&District=&ID=&KeyWord=&Shop=
可簡化為:
https://www.cosmed.com.tw/Contact/Shop_list.aspx?pg=2
最後一頁:
https://www.cosmed.com.tw/Contact/Shop_list.aspx?pg=67&City=&District=&ID=&KeyWord=&Shop=
可簡化為:
https://www.cosmed.com.tw/Contact/Shop_list.aspx?pg=67
觀察網頁原始碼
瀏覽器以滑鼠按右鍵,可以選「檢視網頁原始碼」,或是「檢視元素」,
可以看到網頁的原始碼,網頁主要是以html tag組成。
而我們所需要的門市資訊,被包在 class 為 outletsList 的 div 裡面。
div 裡面包了 table,table 底下有 tr、td。
td 的 class 分別為 TableTitile_OrangeredNo 及 TableItem_OrangeredNo。
<div class="outletsList">
<table width="100%" border="0" cellspacing="0" cellpadding="0">
<tr>
<td class="TableTitile_OrangeredNo">門市名稱</td>
<td class="TableItem_OrangeredNo"><a href="Shop_intro.aspx?ID=521">義聯門市</a>
</td>
</tr>
<tr>
<td class="TableTitile_OrangeredNo">門市地址</td>
<td class="TableItem_OrangeredNo">高雄市燕巢區義大路一段1號B1</td>
</tr>
<tr>
<td class="TableTitile_OrangeredNo">門市電話</td>
<td class="TableItem_OrangeredNo">07-6154503</td>
</tr>
<tr>
<td class="TableTitile_OrangeredNo">營業時間</td>
<td class="TableItem_OrangeredNo">平日:08:00-22:00<br>假日:08:00-22:00</td>
</tr>
</table>
</div>
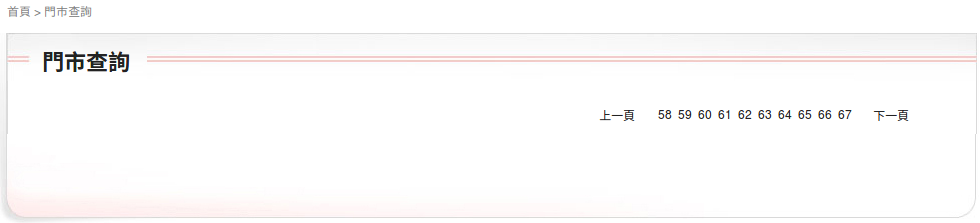
再來是如何得知總共有多少頁呢?
在網址列輸入 https://www.cosmed.com.tw/Contact/Shop_list.aspx?pg=999
可以看到: 「上一頁 58 59 60 61 62 63 64 65 66 67 下一頁」
得知最後一頁是「67」
以html原始碼來說,先找到 class 為 btn-digitALL 的 div,
再找到最後一個 class 為 btn-digit 的 div,就可以知道最後一頁=67>
(為方便閱讀,我有斷行排版)
<div class="btn-digitALL">
<div class="btn-digit-left"><a id="ctl00_BaseContentPlaceHolder_DataPagerControl1_hlPrevious" href="/Contact/Shop_list.aspx?pg=998&City=&District=&ID=&KeyWord=&Shop=">上一頁</a></div>
<div class="btn-digit"><a href="/Contact/Shop_list.aspx?pg=58&City=&District=&ID=&KeyWord=&Shop=">58</a></div>
<div class="btn-digit"><a href="/Contact/Shop_list.aspx?pg=59&City=&District=&ID=&KeyWord=&Shop=">59</a></div>
<div class="btn-digit"><a href="/Contact/Shop_list.aspx?pg=60&City=&District=&ID=&KeyWord=&Shop=">60</a></div>
<div class="btn-digit"><a href="/Contact/Shop_list.aspx?pg=61&City=&District=&ID=&KeyWord=&Shop=">61</a></div>
<div class="btn-digit"><a href="/Contact/Shop_list.aspx?pg=62&City=&District=&ID=&KeyWord=&Shop=">62</a></div>
<div class="btn-digit"><a href="/Contact/Shop_list.aspx?pg=63&City=&District=&ID=&KeyWord=&Shop=">63</a></div>
<div class="btn-digit"><a href="/Contact/Shop_list.aspx?pg=64&City=&District=&ID=&KeyWord=&Shop=">64</a></div>
<div class="btn-digit"><a href="/Contact/Shop_list.aspx?pg=65&City=&District=&ID=&KeyWord=&Shop=">65</a></div>
<div class="btn-digit"><a href="/Contact/Shop_list.aspx?pg=66&City=&District=&ID=&KeyWord=&Shop=">66</a></div>
<div class="btn-digit"><a href="/Contact/Shop_list.aspx?pg=67&City=&District=&ID=&KeyWord=&Shop=">67</a></div>
<div class="btn-digit-right"><a id="ctl00_BaseContentPlaceHolder_DataPagerControl1_hlNext" href="/Contact/Shop_list.aspx?pg=67&City=&District=&ID=&KeyWord=&Shop=">下一頁</a></div>
</div>
透過對網頁元素的觀察,我們才能找出規律,以程式碼來解析網頁html的資訊。
程式碼
本來想寫一段說明我的程式的,但寫了一些覺得有點冗長,
所以,請先直接看我的Github囉。
Github repositories:
* R - rvest版本:
olycats/cosmed-store-list-r: crawler for COSMED store information via rvest
* Python - BeautifulSoup版本:
olycats/cosmed-store-list-py: crawler for COSMED store information via Python BeautifulSoup
* 另外我也把屈臣氏的門市列表拿來做練習:
olycats/watsons-tw-store-finder: crawler for Watsons Taiwan store information via Python BeautifulSoup
覺得比較麻煩的就是「營業時間」這個欄位,必須要轉換斷行符號。
屈臣氏的營業時間也是一樣,除了要轉換斷行符號,還要把多餘的空白移除。